
Googleは検索意図の理解を促進するためにBERTモデルを導入したとThe Keywordで発表しましたので、その内容を和訳してお伝えします。BERTによって文脈を理解するようになった感じですね。

BERTの紹介
BERTとは、“Bidirectional Encoder Representations from Transformers”の略で、直訳すれば“翻訳型双方向符号化表現”ってなりますね。自然言語処理の一つで、私は文脈から検索による信号化と意味化を行き来できる機能のようなイメージを持っています。
これまで以上に検索を理解するために
ここまで15年以上にも渡ってGoogle検索についての仕事を通して学んだことが1つあるとしたら、それは人々の好奇心は常に絶えないということでしょう。Googleでは日々数十億もの検索を確認していて、それらのうち15%のクエリは今までに見たことがないものであり、そういった予測することができないクエリに対して検索結果を返すための方法を生み出してきました。
皆さんや私たちが検索する際、Googleは、検索意図を最適に表現するクエリが何なのかを常時把握しているわけではありません。最低限、どういった単語を使うほうが正しいのか、どんな文字の綴りなのか等は分かるでしょうが、何かを学ぶために検索するわけですから、ほとんどのケースにおいて必ずしもその知識を持ち合わせている必要はありません。
根本的には、検索とは言語理解をすることです。Googleの仕事は、検索ユーザーがどのように入力したとしても、どのように単語を組み合わせたとしても、探しているものを理解し、Webから便利な情報を引き出すことです。長年に渡って言語理解の能力を改善させ続けてきた一方で、特に複雑なクエリや会話的なクエリについては未だに正しく理解することができないこともあります。実際それが検索ユーザーに「キーワードのようなもの」を使わせてしまっており、Googleが理解しやすいように複合単語を組み合わせて入力させてしまっている理由の1つですが、それは一般的に使用している自然な質問のしかたではありません。
言語理解の科学についての研究チームの最新技術と機械学習により、Googleがクエリを理解する方法はかなり大きな進歩を遂げました。それは過去5年間でももっとも大きな躍進であり、検索の歴史上でも最も大きな前進と言えるでしょう。
BERTモデルを検索に
昨年、私たちはニューラルネットワークを元にしたテクニックを紹介・オープンソース化し、自然言語処理(NLP)の事前学習であるBERTと呼ばれる、翻訳型双方向符号化表現を発表しました。この技術により誰もが最先端の質問に答えるシステムを訓練することが可能になります。
この大きな進歩はGoogleの翻訳についての研究の結果です。語句を1つずつ処理理解するのではなく、語句内の全単語に合わせて意味を処理理解するモデルです。そのため、BERT(モデル)は前後の文脈を考えて、特に検索クエリの裏側に潜む検索意図を理解するのに機能します。
しかし、それにはソフトウェアの進歩だけでは難しく、ハードウェアまで新しくする必要がありました。BERTを使ってGoogleが生んだ機能群は非常に複雑で、これまで使ってきたハードウェアの限界を超えそうになったため、今回初めて最新のCloud TPUを使って検索結果を提供し、それにより検索ユーザーが最適な情報をより早く得られるようになったのです。
クエリを判断する
ここまで技術的な内容についてお伝えしましたが、つまるところ検索ユーザーにはどのような効果をもたらすのでしょうか? BERTは検索順位にも強調スニペットにも適用されますし、必要な情報を探し出すのに優れた役割を果たします。実は検索結果表示については、米国内の英語で検索される10回のうち1回はBERTによる検索理解が働いており、これからGoogleではより多くの言語と地域でも提供できるようにします。
特に、より会話的なクエリや「for」「to」といった前置詞が意味をもつ検索については、Google検索はクエリの文脈を理解することができるようになります。自然な形で検索できるようになるわけです。
これらの改善を始めるにあたり、Googleではこの変更がきちんと便利に働くかどうかを何度もテストしました。以下、検索意図の理解とBERTがよく働いているプロセスの例をいくつかご紹介します。
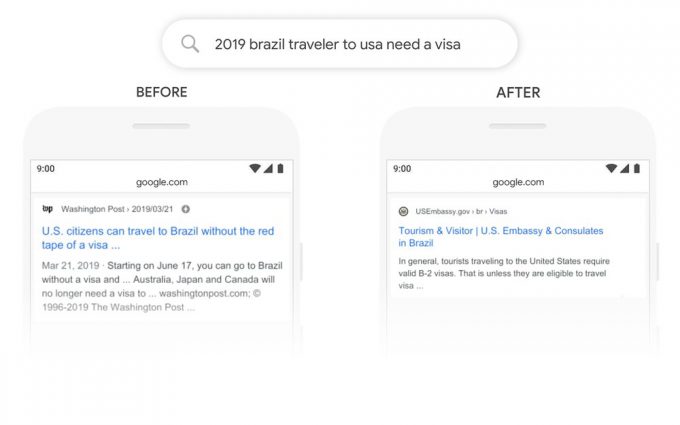
これは「2019年ブラジルからのアメリカ旅行者にビザが必要か」という検索です。「~に(to)」が係る単語と、他の単語との関係性は、このクエリにおいて非常に重要な意味を持ちます。これはブラジル人が、アメリカに旅行することを示しているわけで、その逆ではありません。これまではGoogleのアルゴリズムにはこういった繋がりの重要性を理解できず、アメリカ人がブラジルに旅行する場合の検索結果を表示させることもありました。BERTを利用することで、検索はこのニュアンスを把握できるようになり、「~に(to)」という非常に一般的な単語もこの場合は大きな意味として理解し、このクエリに対してより関連性の高い結果を提供することができます。
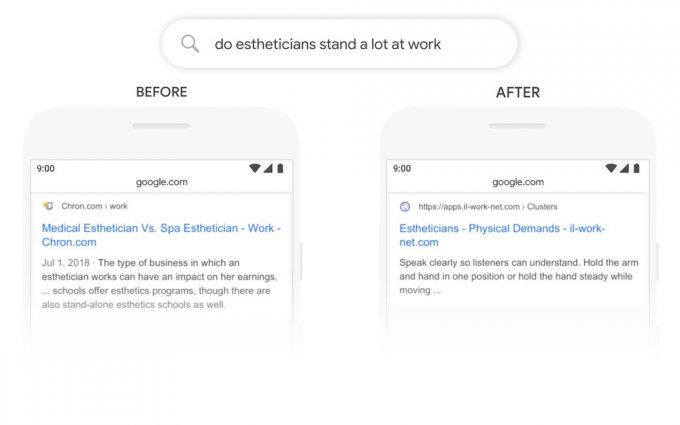
他のクエリの例も見てみましょう:「エステティシャンは仕事中ほとんど立っているか」
以前のGoogleのシステムではキーワードをマッチさせるアプローチを使っていたため、このクエリの場合「立つ(stand)」という単語を「独立の、単体の(stand-alone)」という単語とマッチさせていたはずです。しかし、この文脈上ではその理解は正しくありません。BERTでは「立つ(stand)」が仕事上での身体的な概念と関連があると理解し、より意味のある検索結果を表示できます。
<中略>
より多くの言語で検索を改善
Googleでは世界中の人々がより良い検索結果を得られるようにBERTを適用しています。このシステムの強力な特徴は、1つの言語から学習したことを他の言語にも活かすことができる点です。それにより、(webコンテンツが存在する大多数の言語である)英語圏での改善から学んだことを多言語展開していくことができます。これはGoogle検索が提供される多くの言語でも関連する検索結果を提供することに繋がるわけです。
強調スニペットについては、この機能が利用できて且つかなりの改善が見られる韓国語、ヒンディー語、ポルトガル語など20前後の国でBERTが活かされています。
検索の課題は未解決
検索ユーザーが何を探しているか、どの言語を使うかにかかわらず、Googleはキーワードもどきだけではなく自然な検索語句も使える環境を目指しています。しかし、まだGoogle検索ユーザーを悩ませることも時々あるでしょう。BERTを使おうが、Googleはいつも正しいとは限りません。「ネブラスカの南の州はどれ」と検索した時、BERTの最適解は「サウスダコタ州」になります(もし「カンザスじゃないのか?」と思っていたら、それが正解です)。
言語理解とは継続的な挑戦であり、Googleが検索を改善し続けるためのモチベーションにもなっています。Googleは検索クエリに対して最適な情報を提供できるよう、常に努力し続けています。
引用)The Keywordより和訳
主語述語の理解
要は、「てにをは」を理解したり、文脈上の単語を理解したり、ポイントを掴んだりできるようになったってことですね。「ゲンキ、ナンデモ、ダレ」というカタコト単語じゃなくて「元気があれば何でもできると言ったのは誰?」みたいな助詞やポイントを学習していく機能がBERTのようです。しかも時間の経過(使用量)とともに多言語で精度が上がっていくようですので、これからますます対話型検索が進歩していくのではないでしょうか。
「対話型検索」というとハミングバードが浮かびますが、このBERTもその一環なのでしょうか?
これに関してはまた別の話かもしれませんね。それこそハミングバードを形成するRankBrainはコンテンツ内でのコンテクスト理解のほうで、BERTとしての機能はクエリ理解に関してなのかもしれません。
どちらも検索クエリと検索結果のマッチングという点では、結局同じところにたどり着くのかもしれませんが…。
とにかくこれからは、検索側にもパブリッシャー側にもGoogleはデリケートに反応してくれるということでしょう。
