
Googleは検索クエリに対するマッチングとして、ただのページ単位での概念でなく、コンテンツの一節のみでも最適な回答になっていると判断した場合、検索上位に影響してくる旨を発表しました。Search Onのイベント内で発表したようですが、Twitterでもフォローアップしていましたので、ご紹介したいと思います。
※今回の機能に関しては、このブログの便宜上「文節インデックス」と私が個人的に呼んでいます。実際Googleも「インデックス」という言い方をしたせいで巷では混乱しているようですが、飽くまでも文節単位で評価するイメージですね。

Googleからの発表内容
まずは、Googleがツイートした内容を和訳します。
Last week, we shared about how we will soon identify individual passages of a web page to better understand how relevant a page is to a search. This will be a global change improving 7% of queries:
https://blog.google/products/search/search-on/In this thread, more about how it works….
— Google SearchLiaison(@searchliaison) 2020年10月21日
このスレッドでは、どう機能するかについて詳しくご説明します…
引用)@searchliaisonより和訳
Typically, we evaluate all content on a web page to determine if it is relevant to a query. But sometimes web pages can be very long, or on multiple topics, which might dilute how parts of a page are relevant for particular queries….
— Google SearchLiaison(@searchliaison) 2020年10月21日
引用)@searchliaisonより和訳
With our new technology, we’ll be able to better identify and understand key passages on a web page. This will help us surface content that might otherwise not be seen as relevant when considering a page only as a whole….
— Google SearchLiaison(@searchliaison) 2020年10月21日
引用)@searchliaisonより和訳
This change doesn’t mean we’re indexing individual passages independently of pages. We’re still indexing pages and considering info about entire pages for ranking. But now we can also consider passages from pages as an additional ranking factor….
— Google SearchLiaison(@searchliaison) 2020年10月21日
引用)@searchliaisonより和訳
There’s nothing special creators need to do here. Continue to focus on great content, with all the advice we offer: https://google.com/webmasters/learn/
It just means in some cases, we may now do a better job of surfacing content, no work required on the part of creators.— Google SearchLiaison(@searchliaison) 2020年10月21日
今回の機能が今まで隠れていた良質コンテンツを表面化する手助けになる場合があるだけで、作成者側で作業を行うようなことはありません。
引用)@searchliaisonより和訳
どうでしょう?ご理解いただけましたでしょうか。
要はページ全体のテーマ性で判断して検索順位を決定していたけど、ページ内のコンテンツの中でもそれぞれ分解し、文節(段落と言うほうがイメージしやすいかもです)単位で評価するとのことです。これによって、せっかく的確な1,2文があったにも関わらず埋もれてしまっていた最適コンテンツも陽の目を見ることになるとのことです。しかもこれ、全体の7%に影響するようですので、かなり大きなアップデートと順位変動が予測されるかもしれません。
また、Googleが発表しているSearch Onの記事内から、この文節インデックス(※このブログでの便宜上、私が勝手に命名してますw)の箇所だけを和訳してご紹介します。
Very specific searches can be the hardest to get right, since sometimes the single sentence that answers your question might be buried deep in a web page. We’ve recently made a breakthrough in ranking and are now able to not just index web pages, but individual passages from the pages. By better understanding the relevancy of specific passages, not just the overall page, we can find that needle-in-a-haystack information you’re looking for. This technology will improve 7 percent of search queries across all languages as we roll it out globally.
文節
せっかく検索の回答になる一文があったとしても、それがWebページの中に深く埋もれてしまっていては、検索したところでその回答を発掘するのは非常に難しくなってしまいます。Googleではこの度、Webページを検索順位に反映する際、ページ全体を通して読み込むのではなく、ページ内の文節単位でも個別に読み込むよう、画期的な進歩を遂げました。ページ全体を通してだけでなく文節単位での合致度も理解出来るようになることで、検索者が求めれば、干し草の中から針を探すような情報であっても発掘することができるようになります。この機能によって、グローバルに全言語で検索クエリの7%に影響することが想定されます。
引用)The Keyword
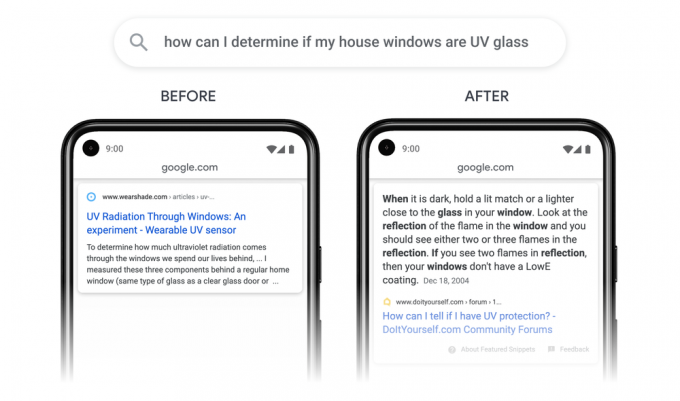
強調スニペット化の話?
検索クエリに対して、該当ページ内の奥深くにある一文でも拾ってランクインさせるということは…検索ユーザーが検索結果からクリックしても、Webページ内でその該当する一文にすぐに辿り着けないのではないでしょうか。該当する一文をハイライトする機能はブラウザによって対応がマチマチですから…。そうなると、Googleにとってもっとも嫌な「検索ユーザーへのストレス」を誘発してしまうわけですよね?
その部分はどうなるんだろう…と思っていたのですが…上図の例を見ると、強調スニペット化されているのが分かります。
つまり、今回の文節インデックス(※勝手に命名してますよ)は、強調スニペット化の話なのでしょうか。検索クエリ全体の7%がこの文節アルゴリズムによって強調スニペット化するということなのでしょうか。または強調スニペット化によって、順位がズレていく(強調スニペットは1位扱いなので)Webサイトページが7%あるということなのでしょうか。
まだまだ全く様子が分かりませんが、強調スニペット化するというなら道理としては分かりやすいですよね? Googleが「インデックス」という言い方をしているのも頷けます。
いつから?
近いうちに反映されそうです。数ヶ月ほどかかるかもしれません。ただ反映されたらまたツイートするようなことをDanny Sullivan氏(Googleの中の人)は言っています。
We’ll update the thread when it goes live.
— Danny Sullivan(@dannysullivan) 2020年10月21日
引用)@dannysullivanより和訳
イマイチまだよく分からない文節インデックス(※勝手に命名)ですが、もうちょっと様子を見たいと思います。
