
米国現地時間3月23日、Twitterは、Twitterブログで「おすすめ」タブのタイムライン(TL)に表示される仕組みについて公開しました。かなりセンセーショナルな情報で、巷ではだいぶ大騒ぎだったのですが、和訳が遅れまして…このタイミングでご紹介します。最近は私も頑張ってTwitterに注力していますので、かなり勉強になりました。

Twitterからの発表内容
Twitterはしばらく前からホームのTLが「おすすめ」と「フォロー中」に分かれています。「フォロー中」は自分がフォローしている人だけのツイートを見ることができますが、「おすすめ」はフォロー中のアカウント以外でも親和性や間接性等、Twitterがおすすめとしてレコメンドするアカウントが含まれます(50:50の割合とのことです)。特に私の肌感覚では一度「いいね」をしたアカウントのツイートはかなりの確率で次のホームのTLに表示されるような気がします。
というわけで、そんなTwitterの「おすすめ」表示のアルゴリズムについての記事を和訳します。
Twitterのレコメンドのアルゴリズムについて
Twitterは、今世界で起きていることの中から最高の情報をお届けすることを目的としています。そのためには、毎日投稿される約5億件のツイートの中から、最終的にあなたの端末の「おすすめ」タブのタイムラインに表示されるトップツイートを抽出するレコメンデーションアルゴリズムが必要です。このブログでは、このアルゴリズムがどのようにあなたのタイムラインに表示されるツイートを選んでいるのかをご紹介します。
私たちのレコメンデーションシステムは、入り組んで構成された様々なサービスや業務によって構成されており、その点を詳しくご説明します。アプリの中でおすすめされるツイート領域は、検索や広告などたくさんありますが、この記事では、ホーム画面の「おすすめ」フィード部分に焦点を当てます。
ツイートの選定方法
Twitterのレコメンデーションの基盤は、ツイート、ユーザー、エンゲージメントデータから潜在情報を抽出する一連のコアモデルと機能によって構成されています。これらのモデルは、「将来、そのユーザーと交流する確率はどのくらいか」「Twitter上のコミュニティとその中でのトレンドツイートは何か」など、Twitterネットワークに関する重要な疑問に回答できるようになることを目的としています。Twitterにとってこれらの疑問に正確に答えることが、より適切なレコメンデーションを提供できることになるのです。
レコメンデーションパイプラインは、以下機能を通した3つの主要なステージで構成されています:
- 候補ソースと呼ぶプロセスで、レコメンド用の異なる情報源から最適なツイートを取得します。
- 機械学習モデルを使用して、各ツイートをランク付けします。
- ブロックしたユーザーのツイート、NSFWコンテンツ(※Not Safe For Work:アダルト系や薬物や犯罪に関する情報等で職場で見ないほうが良い内容)、既に閲覧したツイートを除外する等のヒューリスティック分析とフィルタ機能を適用します。
「おすすめ」タイムラインの構築と配信を担当するサービスは、Home Mixerと呼ばれています。Home Mixerは、コンテンツのフィードを構築するためのScalaのカスタムフレームワークであるProduct Mixerを基盤にしています。このサービスは、様々な候補ソース、スコアリング機能、ヒューリスティック分析、フィルター機能とを繋ぐソフトウェアの骨組みとして機能します。
この図は、タイムラインの主な構成要素を示したものです:
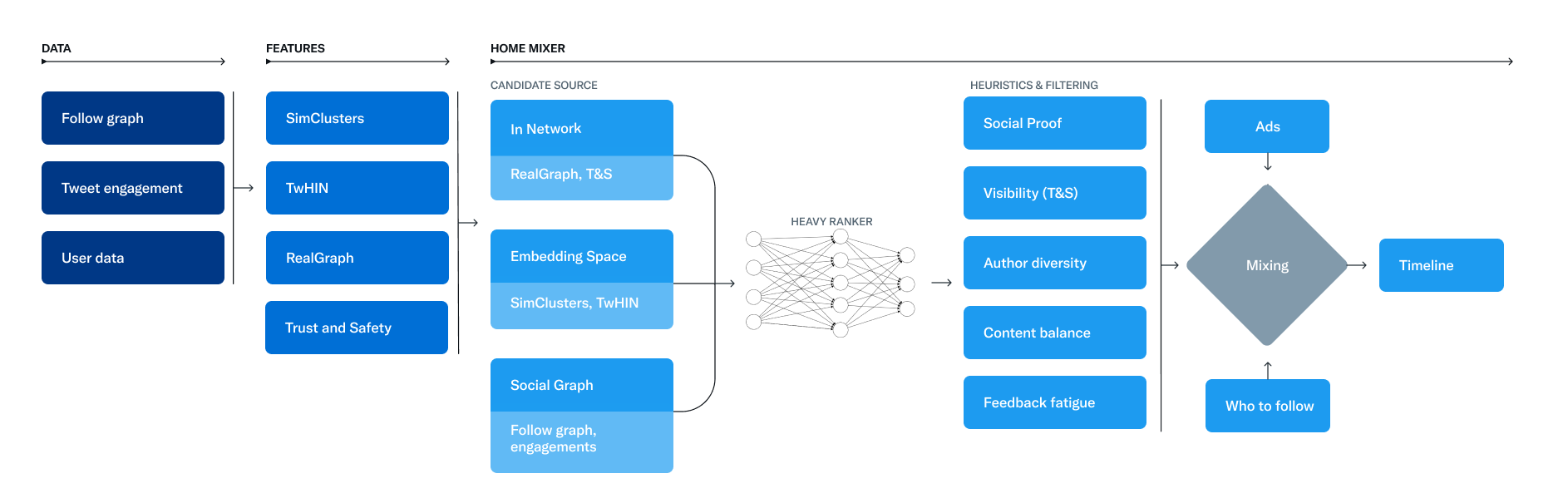
このシステムの主要な部分を、1回のタイムラインリクエストで呼び出される順番に、候補者ソースから候補者を取得するところから見ていきましょう。
Candidate Sources(候補者情報源)
Twitterは、ユーザーの最近の関連ツイートを取得するために使用するいくつかの候補ソースを備えています。各リクエストに対して、これらのソースを通じて数億ある候補の中から最適な1,500ツイートを抽出するようにします。Twitterでは、あなたがフォローしている人(In-Network)とフォローしていない人(Out-of-Network)から候補を見つけます。現在、For Youのタイムラインは、ユーザーによって異なるかもしれませんが、平均して50%のネットワーク内ツイートと50%のネットワーク外ツイートで構成されています。
フォローしている人からの情報源抽出方法
フォローしている人からの情報源抽出方法は最重要の候補ソースであり、あなたがフォローしているユーザーからの最も関連性の高い最新のツイートを配信することを目的としています。ロジスティック回帰分析を用いて、あなたがフォローしているユーザーのツイートを関連性に基づいて効率的にランク付けします。そして、上位のツイートは次の段階に送られます。
ネットワーク内ツイートのランキングで最も重要な要素は、リアルグラフです。リアルグラフは、2人のユーザー間のエンゲージメントの可能性を予測するモデルです。あなたとツイート作成者の間のリアルグラフのスコアが高いほど、その人のツイートがより多く表示されるようになるでしょう。
フォローしている人からの情報源抽出方法は、Twitterで最近採用され出した手法です。12年前から各ユーザーのツイートのキャッシュからあなたがフォローしている人のツイートを抽出するファンアウトサービスを利用していましたが、この度廃止しました。また、数年前にアップデート、学習されたロジスティック回帰分析の再設計も行っているところです!
フォローしていない人の情報源抽出方法
ユーザーのネットワークの外にある関連ツイートを見つけるのは、もっと厄介な課題です:アカウントをフォローしていないのに、そのツイートが自分に関連するかどうかをどうやって判断すれば良いのでしょうか。Twitterは、この問題に対処するために2つのアプローチをとっています。
ソーシャルグラフ
Twitterの初期段階アプローチは、あなたがフォローしている人や同じような興味を持つ人のエンゲージメントを分析することで、あなたが関連性を見出すであろうツイートを推定することです。
エンゲージメントとフォローのグラフをたどり、以下の質問に答えるように機能します:
- 当人がフォローしている人たちは、最近どのようなツイートをしているのか?
- 当人と類似したツイートを「いいね」しているのは誰で、その人たちが最近「いいね」したツイートは何か?
これらの質問に対する答えに基づいて候補となるツイートを抽出し、ロジスティック回帰分析を用いてランク付けします。このようなグラフの探索は、フォローしていない人の情報源抽出方法に欠かせないものです。Twitterは、この抽出機能を実現するために、ユーザーとツイート間のリアルタイムな相互間グラフを生成するグラフ処理エンジンであるGraphJettを開発しました。Twitterのエンゲージメントとフォローのネットワークを解析するこのようなヒューリスティック分析は有用であると分かっています(これらは現在ホームタイムラインのツイートの約15%に対応しています)が、ネットワーク外のツイートのより大きな情報源抽出方法となっているのは、空間ベクトル埋め込み技術です。
空間ベクトル埋め込み技術
空間ベクトル埋め込み技術は、コンテンツの類似性に関するより一般的な問いに答えることを目的としています:どのようなツイートやユーザーが当人の興味と類似しているのか?という問いです。
埋め込み技術は、ユーザーの興味とツイートのコンテンツを定量化することで機能します。そして、この空間ベクトル埋め込み技術における任意の2人のユーザー、ツイート、ユーザーとツイートのペアの間の類似度を計算することができます。正確なベクトルを埋め込むことで、この類似度を関連性という形で扱うことができます。
Twitterの最も有用な空間ベクトル埋め込み技術の1つがSimClustersです。SimClustersは、カスタム行列因数分解アルゴリズムを用いて、影響力のあるユーザーの集団を中心としたコミュニティを発見します。コミュニティは14.5万程あり、これは3週間ごとに更新されます。ユーザーとツイートはコミュニティの空間内にベクトル表現され、複数のコミュニティに所属することもできます。コミュニティの規模は、個人の友達グループの数千人から、ニュースやポップカルチャーの数億人規模まで様々です。下記は最も大きなコミュニティの一例です:
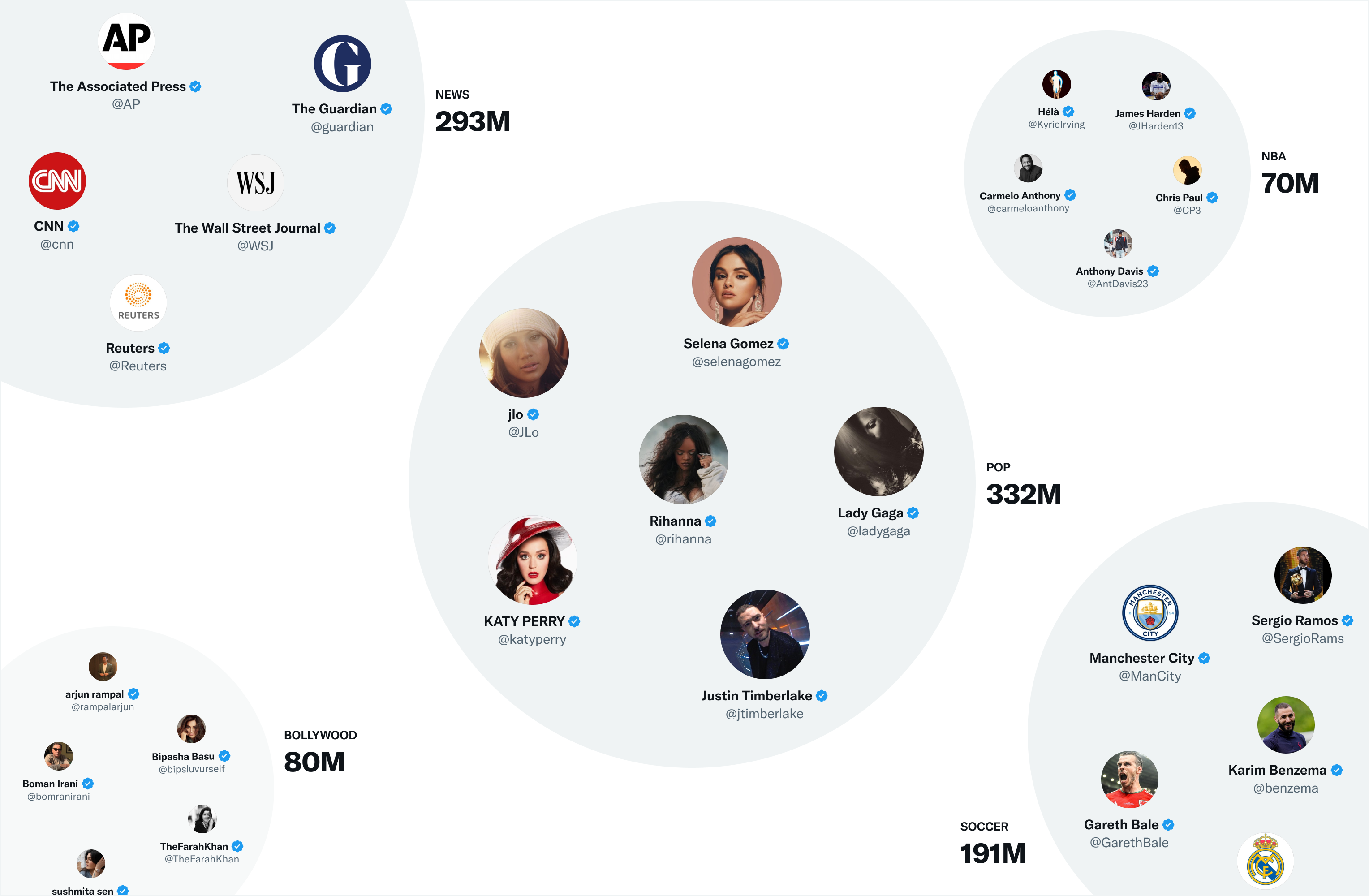
各コミュニティにおけるツイートの人気度を計ることで、ツイートをこれらのコミュニティにベクトル化して組み込むことができます。あるコミュニティのユーザーがそのツイートを気に入れば気に入るほど、そのツイートはそのコミュニティと関連付けられることになります。
ランキング
「おすすめ」タイムラインの目的は、関連性の高いツイートを提供していくことです。そのための方法として、ここまでで関連性のある候補を1,500件ほどに絞っている状態です。そのうえで、その評価方法は各候補ツイートの関連性を直接予測し、タイムライン上のツイートをランク付けするための主要なシグナルとなります。ここでは、どの候補アカウントから発信されたものであるかは関係なく、すべての候補アカウントが平等に扱われます。
ランキングは、ツイートの相互作用を継続的に学習し、肯定的なエンゲージメント(いいね、リツイート、リプライなど)を最適化する、約4,800万パラメータの神経回路ネットワークで構成されています。このランキングメカニズムは、何千もの特徴を考慮し、10個のラベルを出力して各ツイートにスコアを付けます(各ラベルはエンゲージメントの確率を表します)。この評点からツイートがランク付けされます。
ヒューリスティック分析、フィルター機能、生産物の特徴
ランキングの段階を経て、ヒューリスティック分析とフィルター機能を適用して、様々な機能を実装します。これらの機能は、バランスよく多様なフィードを作成するために連携し合っています。ここでいくつかの例を挙げます:
- 可視性フィルタリング:ツイートの内容や好みに応じてフィルタリングを行います。例えば、ブロックやミュートしたアカウントのツイートを除外します。
- 多様性:特定のアカウントからの連続ツイートが多くなりすぎないようにします。
- コンテンツバランス:フォロー中のツイートとフォロー外のツイートが公平にバランスよく配信されるようにします。
- フィードバックに基づく倦怠性:閲覧者が類似したツイートに対してネガティブなフィードバックを提供した場合、特定のツイートのスコアを下げます。
- 社会的保証性:品質保証として、そのツイートと二次的な繋がりがないネットワーク外のツイートを除外します。つまり、当人がフォローしている誰かがそのツイートにエンゲージしているか、そのツイートのアカウントをフォローしているかどうかで判断する機能です。
- 会話性:元のツイートと一緒にスレッド化することで、返信にさらなる文脈(返信元のツイート)を提供します。
- ツイートの編纂:TLに表示されているツイートが既に古くなっている場合、新しく編纂したものに置き換える働きをします。
混合化と提供方法
この時点で、ホーム画面の混合装置は当人の端末に配信されるツイート群のセット準備段階に入っています。最後に、ツイートと広告フォロー推奨、表示するおすすめ機能など、ツイート以外のコンテンツを混ぜ合わせ、当人の端末に改めて整理して表示します。
これらの各手法は1日に約50億回実行され、平均1.5秒未満で完遂します。1回の手法の実行には220秒のCPU時間が必要で、アプリで感じるレイテンシーの150倍近くです。
今回、手法を公開した目的は、Twitterのシステムがどのように動作しているのか、ユーザーの皆様に完全な透明性を提供することを目的としています。Twitterのアルゴリズムをより詳細に理解するために、こちら(とこちら)で閲覧可能なレコメンドの原動力となるコードを公開し、Twitterのアプリ内でより透明性を提供するための機能にもいくつか取り組んでいます。さらに、Twitterが計画している新しい開発には、以下のようなものがあります:
- クリエイターのためのTwitter分析プラットフォームを強化し、リーチやエンゲージメントに関する情報をより多く提供すること。
- ツイートやアカウントに貼られた安全ラベルの透明性をより高めること。
- ツイートがタイムラインに表示される理由をより深く理解できるようにすること。
次はどうする?
Twitterは、世界中で行われている会話の中心にいます。毎日1,500億以上のツイートが人々の端末に配信されています。ユーザーに最適なコンテンツを提供することは、困難であると同時に刺激的な問題でもあります。Twitterは、新リアルタイム機能、埋め込み機能、ユーザー表現など、レコメンデーションシステムを拡張する新しい挑戦にも取り組んでいます。Twitterは、未来の街の広場を作っているのです。もしあなたがこのことに興味を持たれましたら、ぜひ私たちの仲間になってください。
引用)blog.twitter.comより和訳
最後に採用担当宛への連絡先を記すなんて…先日あれだけ大規模なリストラを行ったにも関わらず…エンジニアのほうはより優秀な人を募集しているってことですかね(笑)。
ちなみに本文内にもありますが、こちらのTwitterにおけるTLの表示アルゴリズムのオープンソースを辿れば、それぞれのエンゲージメント等のインパクト度が分かります。最近、画像添付が多くなっているのも、表示アルゴリズムに優遇されているから等が考えられます。他にも世界的に解析している人が書いている記事も参考になるでしょう。例えばヘビーランカーの評価アルゴリズムはこちらの海外の一般プログラマーのブログ記事にも書いてあります(投稿後2分以内の「いいね」は通常の「いいね」の22倍とか!プロフを見て投稿を「いいね」したら通常の「いいね」の24倍とか)。
他にもコードを読み解いていくと「いいね」のインパクトやリプライのインパクト、Twitter Blueアカウントの優遇度合い等、詳細が記されているようですが、いずれにしてもTwitterはもっと一般ユーザーに分かりやすいようにしていくとのことですので、いずれにしても明示されるようになるのではないでしょうか。
SEOに似てきた?
こうしてTwitterのTL表示アルゴリズムが明確になることで、画像を多用したり、いいね!やリプを売ったりする等、TLの表示支援業者が出現したりしそうですね…。なんか10年以上前のSEO業界を彷彿とさせるような…。
しかし、結局SEOが「検索ユーザーにとって有益な情報を提供する」という方向性で定性的観点で落ち着いたように(え?まだ落ち着いてない??)、Twitterも「誰に何を提供したいのか」に尽きる気がします。特にTwitterでビジネスを考えているのであれば尚のことですが、愚痴や日々の意識高いツイート(だけ)ではなく、フォローしてもらいたい人はどんな人なのか、しっかりとフォーカスし、その対象者にとって幸せになる、有益になる情報は何なのかを考察し、ツイートし続けることが大事なのかな、と。
そして、それを何ヶ月、何年も行っていくうちに、フォロワーが「この人の言うことなら聞いてみたいなぁ」「この人の営業やサービスを受けてみたいなぁ」と思われるほどのペルソナになることが大事です。そのために以下の2パターンのアプローチが考えられます。
- 自分を曝け出し、日々の動きを知ってもらうことで“個人”として好きになってもらう
- 発信する情報そのものに魅力を感じてもらい“知”として信頼を得る
どっちの道を選ぶかは、発信者の個性に応じてでしょうが…いずれにしても簡単ではありませんし、一朝一夕にできることではありません。何より、誰もがビジネス機会(どうやって予算をもらえるか)を窺っているような状態で、誰もが「いいね!」を欲しがっている状態ですから。そんなビジネスマン同士の中で、一定以上の評価をもらうなんて相応の努力が必要でしょう。
いずれにしても今後のTwitterに目が離せませんね。
私は…とにかく今はTwitterをやり続けることだけに注力していて、ビジネスなんて先のまた先だと思っています(笑)。まだまだよちよち歩きです。
