
先日、あるサイトで「サイト立ち上げて数日経つがなかなかインデックスされない」とのご相談を受け、検証したところ、Google Search Consoleにrobots.txtを送信しているにも関わらずrobots.txtを作っていなかったせいもあり、500エラーを返していることが分かりました。そのせいで、Googlebot側が「サーバーエラーならサイトを回遊してはいけないな(許可されていないな)」と解釈し、結果クローリングされずインデックスもされない、という現象になっていることが分かりました。
そこで今回は、改めて“robots.txtをリクエストした際のステータスコードとGooglebotの解釈について”をご紹介しておきたいと思います。

今回の事象を紹介
今回、起こった事象をご紹介したいと思います。
繰り返しますが、新規Webサイトを立ち上げてもインデックスがされていない状態でした。色々調べてみたのですが、meta情報等も含め特に特別な設定はしていなかったので、念のためrobots.txtを確認してみたところ、robots.txtが500エラーを返している状態でした。しかし、Google Search Consoleにはrobots.txtを送信しているようで、以下の表示がされていました。
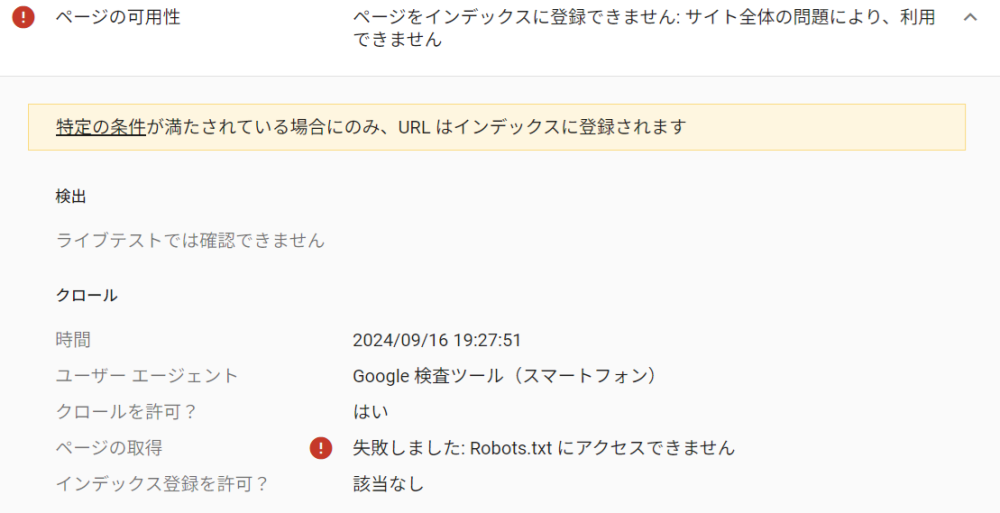
robots.txtが500番台のエラーを返している場合、Googleは“クロールが許可されていない”と判断します。
5xx(server errors)
robots.txtリクエストに対してサーバーから明確な応答がないため、Googleは一時的な5xxおよび429のサーバーエラーと解釈し、サイトが完全に許可されていない場合と同様に処理します。Googleは、サーバーエラー以外のHTTPステータスコードを取得するまでrobots.txtファイルのクロールを試行します。503(service unavailable)エラーの場合、再試行が頻繁に行われます。robots.txtに30日以上アクセスできない場合、Googleはrobots.txtの最後のキャッシュコピーを使用します。使用できない場合、Googleはクロールに対する制限はないと見なします。
クロールを一時的に停止する必要がある場合は、サイト上のすべてのURLで503 HTTPステータスコードを返すことをおすすめします。
Googleは、サイトが誤って構成されているためにページ不明の404ではなく5xxが返されていると判断できる場合、そのサイトからの5xxエラーを404エラーとして扱います。たとえば、5xxステータスコードを返すページのエラーメッセージが「ページが見つかりません」の場合、Googleはそのステータスコードを404(not found)と解釈します。
robots.txtが404の場合は、問題なくクロールされるようですので、そもそもファイルが無ければまだ良かったのですが、500エラーを返してしまったのでクロールを拒否している形になってしまいました。
その後、このWebサイトでは、robots.txtを正常に設定したことで、クロールとインデックスが始まったのですが、当事者としては焦りますよね。
他にもHTTPステータスコードによってクローラーの解釈は異なる
今回はrobots.textの500エラーによる弊害が起こりましたが、他にもrobots.txtが2xx系、3xx系、4xx系、その他のエラーによってGooglebotの解釈がそれぞれ異なります。詳しくはGoogle公式の「Googleによるrobots.txtの指定の解釈」をご確認ください。このGoogle公式ドキュメントにはHTTPステータスコード以外にもrobots.txtのキャッシュや構文ルール、ファイル形式等も説明してくれていますので、一読しておくと良いと思います。特に構文における対象フィールドは知っておくと役に立ちます。
robots.txtはサイト訪問者には関係ないからといって侮るなかれ、です。GoogleとWebサイトのクロールを繋ぐ大事な指示ファイルですので是非ご参考ください。
