
先日の6月23日、GoogleはGooglebotのドキュメントを更新し、「最初のクローリングにおいてGoogleがインデックス対象とするのは、15MBまで」という記載を追加しました。とはいえ、しょせんHTML等のソースベースですので(半角1文字が1byte)、1,500万文字。全角日本語でも750万文字(ソースベースなのでタグ等も含みますが)で、原稿用紙で18,750枚…。そんなファイルを私は見たことないので、ほぼ無視していましたが、そのフォローアップ記事としてSearch Central Blogが取り上げていましたので、和訳してご紹介します。
15MBを超えることなんて無い?
冒頭で述べたように、Googlebotの初回読込(インデックス)制限が15MBと記載されているからといって特段気にすることはないかと思いますが…充分理解できていない人が世界中にいるようでして…。おそらくページ内にエンベッドした動画や画像のサイズ容量も加算して考えてしまっているのではないかと思います。確かにそういう意味ではGoogleが説明足らずだったのかもしれません。というわけで、そんなSearch Central Blogの内容です。
Googlebotと15MBの件
ここ数日、Googlebotに関する技術ドキュメントの更新について、多くのご質問をいただきました。つまり、Googlebotは特定のファイル種類を取得する際に、最初の15メガバイト(MB)しか“見ない”ことを文書化しました。このしきい値は今回新しく設定されたわけではなく、何年も前から存在するものです。デバッグの際に役立つかもしれないことと、めったに変更されないことから、ドキュメントに追加したにすぎません。
この制限は、Googlebotが最初にリクエストしたときに受け取ったバイト数(コンテンツ)にのみ適用され、ページ内で参照されたリソースには適用されません。例えば、https://example.com/puppies.htmlを開くと、ブラウザは最初にHTMLファイルをダウンロードし、そのバイト数に基づいて、JavaScriptや画像など、HTML内のURLで参照されているものに対してさらにリクエストを行うかもしれません。ブラウザ同様、Googlebotも同じことをします。
この15MBという制限は、どのような意味を持つのでしょうか?
おそらくそれ以上でもそれ以下でもなく、何の意味もないでしょう。インターネット上では、これより大きなサイズのページはほとんどありません。HTMLファイルのサイズの中央値は30キロバイト(kB)と、15MBの約500分の1なので、皆様がそのようなサイズのページを作ることはまずないでしょう。しかし、もし15MBを超えるHTMLページのオーナーなら、せめてインラインスクリプトとCSSダストを外部ファイルに移動するようにしてください。
15MBを超えたコンテンツはどうなるのですか?
最初の15MB以降のコンテンツは、Googlebotによるクロールが停止され、最初の15MBのみがインデックスされます。
15MBの制限はどのような種類のコンテンツに適用されますか?
15MBの制限は、Google検索でサポートされているファイル形式のコンテンツに適用され、Googlebot(スマートフォン版Googlebot、デスクトップ版Googlebot)が取得する際に利用されます。
Googlebotが画像や動画を見なくなるということですか?
いいえ。Googlebotは、HTML内でURLによって参照されているビデオや画像(例えば<img src=”https://example.com/images/puppy.jpg” alt=”cute puppy looking very disappointed” />など)に関して、別途同時並行して検知しています。
データURIはHTMLのファイルサイズを増加させますか?
はい。データURIはHTMLファイル内に存在するため、データURIを使用するとHTMLファイルサイズが増加します。
ページのサイズを調べるにはどうしたら良いですか?
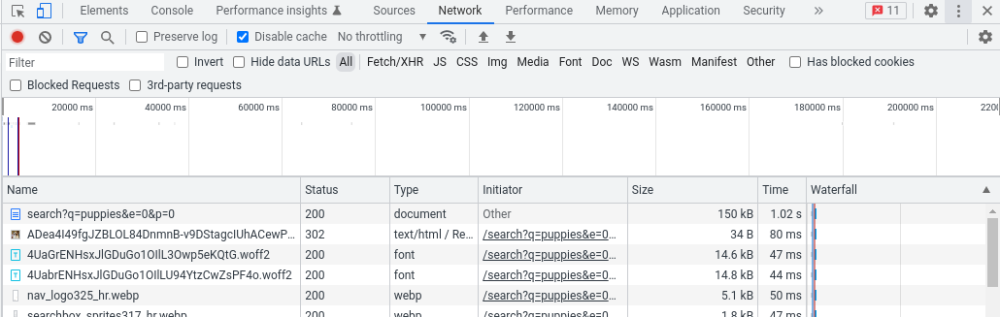
いくつかの方法がありますが、最も簡単なのは、ブラウザとそのデベロッパーツールを使う方法です。通常通りページを読み込んでから、デベロッパーツールを起動し[ネットワーク]タブに切り替えてください。ページを再読み込みすると、ページを表示するためにブラウザが行った全てのリクエストが表示されるはずです。一番上のリクエストは、[サイズ]列にページのバイトサイズが表示されているものです。
例えば、Chromeのデベロッパーツールでは、このように表示され、サイズ欄には150kBと表示されます。
もっと自分で挑戦してみたい上級者の場合は、コマンドラインからcURLを使用することもできます。
-A “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36” \
-so /dev/null https://example.com/puppies.html -w ‘%{size_download}’
他にもご質問がある場合は、TwitterやSearch Central Forumsでも受け付けています。また、ドキュメントについても詳細説明が必要とお感じであれば、ぜひ対象ページ自体のフィードバックからお知らせください。
引用)Search Central Blogより和訳
気にするな
Googleの方で、従来の仕様を改めて記載したところ、サイトオーナーがびっくりして問い合わせが増えたって感じの印象を受けます。そして、あくまでもGooglebotが読み込むのはファイル自体のソースで、その中に記載されている画像ファイルの容量等は15MBの検知対象外です。それは別途並行して読み込んでくれるので問題ありません。敢えていうなら、そのファイルパス(URL)が15MBの検知対象となります。
というわけで、気にしないで大丈夫です。
