
Googleは米国現地時間12月3日、Search Central Blogを更新し、GoogleのクローラーがどうやってWebページを処理しているかを解説しました。Googlebotのクロールの仕組みやJavaScriptやCSSを読み込むタイミング、クロールバジェットを最適化するための心得、クロール状況の確認方法等の基礎的な情報も紹介してくれていますので、記事内容を和訳してご紹介します。
![]()
クロールの正体を知る
記事では、以下の内容について順序立てて説明してくれています。
- クロールについての説明
- HTMLとJavaScript、CSSのクローリングのタイミングやキャッシュ
- クロールバジェットを最適化してスムーズにクロールしてもらう方法
- クロール状況の確認方法
まずは和訳した内容をご覧ください。
クロールの12月:Googlebotのクロール方法とその理由
WebページがGoogle検索結果に表示される前に、Google検索で少し作業が必要とされることはご存知かもしれません。これらのステップの1つはクロールと呼ばれています。Google検索のクロールはGooglebotによって実行されます。GooglebotはGoogleのサーバー上で稼働するプログラムで、URLを取得し、ネットワークエラー、リダイレクト、その他Webを巡回する際に遭遇する可能性のある小さな問題に対処します。しかし、クロールについてあまり語られない詳細事項もいくつか存在します。今月は毎週、それらの詳細事項のいくつかを取り上げ、ユーザーのサイトのクロール方法に大きな影響を与える可能性がある情報について掘り下げていきます。
おさらい:クロールとは何か?
クロールとは、新しいWebページを発見し、更新されたWebページを再訪問し、それらをダウンロードするプロセスです。簡単に言うと、GooglebotはURLを取得し、そのURLをホストしているサーバーにHTTPリクエストを送信し、そのサーバーからの応答を処理します。場合によってはリダイレクトに従い、エラーを処理し、ページコンテンツをGoogleのインデックスシステムに渡します。
しかし、最近のWebページは純粋なHTMLだけではないため、ページを構成する他のリソースをクロールする場合はどうでしょうか? これらのリソースをクロールすると“クロールバジェット”にどのような影響があるのでしょうか? これらのリソースはGoogle側でキャッシュ可能なのでしょうか?また、これまでクロールされていないURLと、既にインデックスされているURLの間には違いがあるのでしょうか?この記事では、これらの質問、そしてそれ以上の質問にもお答えします!
Googlebotとページリソースのクロール
最新のWebサイトではHTMLを超えて、JavaScriptやCSSなどの異なるテクノロジーを組み合わせることで、ユーザーに活気のある体験や便利な機能を提供しています。このようなページにブラウザでアクセスすると、まずユーザー向けのページを構築を開始するために必要なデータをホストする親URLがダウンロードされます。つまりページのHTMLです。この初期データには、JavaScriptやCSSなどのリソースへの参照が含まれている場合がありますが、画像や動画も含まれている場合があり、ブラウザはそれらを再度ダウンロードして最終的なページを構築し、ユーザーに表示します。
Googleも全く同じことをしますが、若干異なります:
- Googlebotが親URLから初期データをダウンロードする(つまりページのHTML)
- Googlebotが取得したデータをウェブレンダリングサービス(WRS)に渡す
- Googlebotを使用して、WRSが初期データで参照されたリソースをダウンロードする
- WRSがユーザーのブラウザと同様に、ダウンロードしたすべてのリソースを使用してページを構築する
ブラウザと比較すると、ページのレンダリングに必要なリソースをホスティングするサーバーの負荷など、スケジューリングの制約により、各ステップ間の時間が大幅に長くなる場合があります。そして、ここでクロールバジェットの話が出てきます。
ページのレンダリングに必要なリソースをクロールすると、そのリソースをホストしているホスト名のクロールバジェットを消費することになります。これを改善するために、WRSはレンダリングするページで参照されるすべてのリソース(JavaScriptおよびCSS)をキャッシュしようと試みます。WRSキャッシュの有効期間は、HTTPキャッシュに関する指示シグナルの影響を受けない代わりに、WRSはすべてを最大30日間キャッシュし、他のクロールタスクのためのクロールバジェットを確保します。
サイトオーナーの観点では、クロール対象のリソースをどのように管理するかによってサイトのクロールバジェットに影響を与える可能性があります。Googleでは、以下を推奨しています:
- ユーザーに優れた体験を提供するため、可能な限りリソースを最小限に抑える。ページのレンダリングに必要なリソースが少なければ少ないほど、レンダリング時のクロールバジェットも少なくて済みます。
- キャッシュバスターパラメータは慎重に使用する:リソースのURLが変更された場合、コンテンツが変更されていない場合でもGoogleはリソースを再度クロールする必要があるかもしれません。もちろん、これはクロールバジェットを消費することになります。
- CDNの利用や、リソースを異なるサブドメインにホスティングするなどして、メインサイトとは異なるホスト名でリソースをホストします。これにより、クロールバジェットに関する懸念は、リソースを配信するホストにシフトされます。
★ 2024年12月6日更新:別のホスト名への接続負荷によりページのパフォーマンスが低下する可能性があるため、 ページのレンダリングに必要な重要なリソースにはこの方法はお勧めしません(JavaScriptやCSSなど)。ただし、ビデオやダウンロードなどの重要でない大規模なリソースの場合には、この方法は充分価値があります。
これらの点は、メディアリソースにも当てはまります。Googlebot(具体的には、Googlebot-ImageやGooglebot-Video)がそれらを取得した場合、サイトのクロールバジェットが消費されます。
robots.txtで拒否するようにしたくなるでしょうが、レンダリングの観点から、リソースのクロールを拒否すると通常は問題が発生します。WRSがレンダリングに重要なリソースを取得できない場合、Google検索はページのコンテンツを抽出できず、検索結果にページを表示できなくなる可能性があります。
Googlebotのクロール状況を確認するには?
Googleがクロールしているリソースを分析する最良の情報源は、ブラウザやクローラーからリクエストされた全URLのアクセス状況が記載されているサイトの生のアクセスログです。アクセスログでGoogleのクローラーを特定するために、開発者向けドキュメントにGoogleのIP範囲を公開しています。
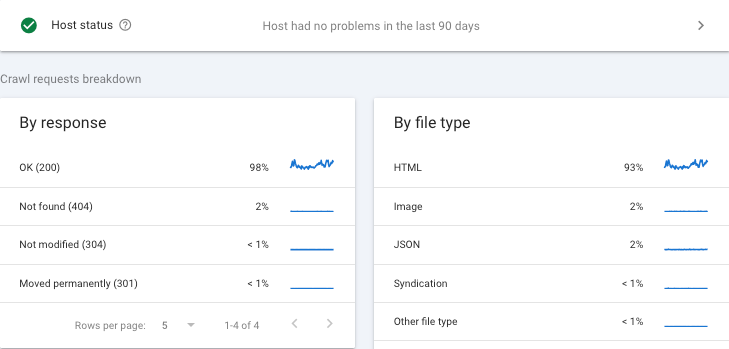
次に有効なリソースは、もちろん、Search Consoleのクロール統計情報レポートで、このレポートではクロールごとに各リソースの種類が分類されています。
最後に、クロールやレンダリングに本当に興味があり、他のユーザーとそれについてやり取りしたい場合は、Search Centralコミュニティが最適ですが、LinkedInでも対応可能です。
この仕組みを知っておくことで、JavaScriptで生成されたコンテンツのクローリングやランキングへの寄与タイミングについての感覚が分かるかと思います。また、やはりパラメータ付URLが発生すればするほど、クロールバジェットもそちらに割かれることは再認識しておくと良いですね(だからこそ、デフォルトで自己参照canonicalを入れておくことは有効です)。先日、あるデータベース系サイトでセッションパラメータやサイト内検索結果パラメータが自動生成されてしまうことでクロール負荷が発生してクロール頻度が落ちる、といった現象が生じてしまい、それを鎮火するのに苦労しました。
クロール状況を知るのは大事
私たちのSEOコンサルテーションにおいては、クロール状況も月次レポートとして提出しています。そして何かあった場合、すぐに理解・解決策提示・実行ができるよう、常時取引先企業様にはクロールのされ方についてご説明しています。
クロールの頻度が高ければ高い程、ページを正しく、精度も高く評価してくれるはずだと思います(より多くのアルゴリズムが査定するので統計として正確になっていくのではないかと考えています)。ですのでクロール頻度を高めるために、(サイトの大きさ等、Google側で取り決める要素は多く、能動的なコントロールはできないものの)少しでも通気性の良いサイトを作るよう心掛けていきましょう。分かりやすく綺麗なサイト構造、内部外部リンクの徹底、ファイル名、表示速度、XMLサイトマップ、インデックス状況の確認等、やることはいっぱいありますよ!
